





I. Introduction▲
Hibernate permet aux développeurs de s'affranchir des nombreuses problématiques liées à la gestion d'une base de données. Le niveau d'abstraction est tel (utilisation de POJO, sauvegarde automatique, etc.) qu'un mythe veut que l'utilisation de la librairie de persistance ne nécessite peu ou pas de connaissance des mécanismes sous-jacents.
C'est hélas non seulement faux, mais également dangereux pour la survie de votre application. En effet, sur un domaine aussi sensible que le chargement de données, se reposer aveuglément sur les mécanismes natifs d'Hibernate peut vous mener droit à la catastrophe. Petite revue des options disponibles…
II. Notions fondamentales▲
La manipulation des entités Hibernate se limite rarement à des objets sans lien les uns avec les autres. Au contraire, les bases de données relationnelles mettent en œuvre toute une panoplie d'index reliant les enregistrements les uns aux autres. Hibernate permet la manipulation de ces enregistrements sous forme de graphe d'objets, que l'on peut représenter sous la forme d'un arbre :
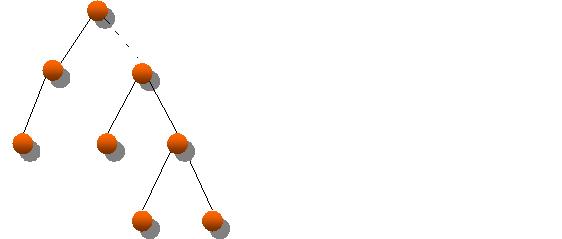
Or le chargement d'un tel graphe d'objet peut s'avérer coûteux en temps d'exécution (bien plus qu'en occupation mémoire), d'où l'impérieuse nécessité de les remplir avec soin et parcimonie.
III. Le chargement à la demande▲
III-A. Principe▲
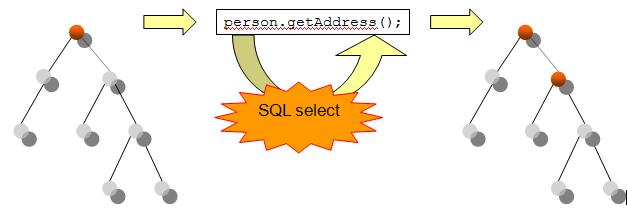
Le chargement à la demande (ou « lazy loading ») est la stratégie native mise en œuvre par Hibernate. Elle consiste à ne charger que le minimum de données, puis de générer une nouvelle requête SQL pour récupérer les données supplémentaires lorsque celles-ci seront demandées par le programme.
Dans la pratique, Hibernate charge tous champs de la table principale, et les clés étrangères sont stockées sous forme simplifiée (seul l'ID est renseigné), ce que l'on nomme un proxy. Lorsque le programme essaiera d'accéder aux membres de ce proxy, Hibernate générera une requête SQL et récupérera les données nécessaires afin de le remplir…
III-B. Avantage▲
Le principal avantage du lazy-loading est bien entendu sa transparence. Le programme utilise les objets du Domaine en toute simplicité, et seules les données vraiment nécessaires sont chargées.
III-C. Inconvénients▲
Si séduisante qu'elle puisse paraître, cette approche présente les défauts suivants :
- absence de maîtrise du chargement : chaque appel peut potentiellement provoquer une requête en base de données, et ce, de manière complètement transparente et incontrôlable. On peut ainsi assister à des effondrements spectaculaires des performances de l'application, dus à un excès de requêtes SQL. De plus, l'utilisation de certaines librairies, basées notamment sur l'introspection – telles que JAXB ou Dozer – provoque le chargement de la totalité du graphe d'objet lors de la sérialization du graphe d'objets ;
- N+1 select : corollaire du point précédent, le chargement de collections se traduit par un nombre rédhibitoire de requêtes. Regardons l'exemple suivant :
List<Address> addressList = person.getAddressList() ; (1)
for (Address address : addressList)
{
displayCity(address.getCity(), address.getZipCode()) ; (2)
…
}L'appel (1) génère une requête SQL remontant la liste des identifiants des adresses composant la liste, et que chaque appel (2) génère une autre requête SQL afin de remplir la totalité de l'objet Address, soit au total N+1 requêtes (N étant la cardinalité de la liste).
Seule solution, non pas pour maîtriser, mais pour diagnostiquer ce genre de problématique : passer le paramètre de configuration « show_sql » à 'true' afin de visualiser en développement les requêtes générées automatiquement par les proxies Hibernate.
IV. Eager fetching▲
IV-A. Principe▲
Solution diamétralement opposée au chargement à la demande, le « eager-fetching » consiste à systématiquement charger l'intégralité du graphe d'objets associés.
Techniquement, il suffit d'ajouter l'attribut « lazy » à 'false' (ou fetch='join') pour toutes les associations (one-to-one, many-to-one, one-to-many) et le tour est joué.
IV-B. Avantage▲
Tout comme le chargement à la demande, cette stratégie de chargement présente l'avantage de la simplicité. De plus, une fois la donnée chargée, cette dernière est entièrement et immédiatement disponible, sans génération de requête SQL supplémentaire.
IV-C. Inconvénient▲
Vous l'aurez deviné, là où le bât blesse, c'est justement au temps de chargement de votre graphe d'objets, qui peut vite s'avérer rédhibitoire avec un schéma classique (quelques associations suffisent à faire exploser les performances).
Si on y ajoute une grande propension au syndrome du produit cartésien (cf. encadré), vous comprendrez bien que cette approche est à bannir de toute application manipulant un graphe d'objet un tant soit peu conséquent.
Règle n°1 : pas plus d'une collection à la fois
Le chargement des collections (association many-to-one, coté « one ») est un point délicat de la programmation avec Hibernate.
En effet le chargement de plusieurs collections en parallèle risque de fortement dégrader les performances de votre application, car une telle requête remonte en général trop de données (produit cartésien). En effet, le résultat de la requête SQL est composé de la combinaison des résultats possibles sur chaque jointure, comportant une multitude de doublons qu'Hibernate devra éliminer.
À titre d'exemple, une requête renvoyant 100 éléments, chacun associé à deux collections de 10 éléments chacun, serait constituée de (100*10*10) = 10 000 lignes de résultats.
Outre le temps de traitement par Hibernate, le temps de transfert d'un tel volume de résultat achèvera de réduire les performances de votre application à néant !
V. Chargement explicite▲
V-A. Principe▲
L'idée directrice est ici de définir à l'avance les associations qui seront nécessaires à l'affichage ou au traitement d'une entité, puis de les charger en une seule requête. Cela tombe plus ou moins sous le (bon) sens : on définit une fois pour toutes ce dont on a besoin et on le charge, sans recours à une fonctionnalité « magique » qui fait le boulot en aveugle.
Ainsi, la couche d'accès aux données se décompose en plusieurs méthodes de chargement (par exemple loadPersonAndAddress, loadPersonAndFamily, loadPersonAddressAndFamily…), chacune décrivant le chargement associé.
Techniquement, les requêtes sont plus complexes qu'un simple chargement Hibernate : il faut définir explicitement les jointures qui seront chargées par la méthode :
StringBuilder hqlQuery = new StringBuilder();
hqlQuery.append("from A a");
hqlQuery.append(" inner join fetch a.b1");
hqlQuery.append(" inner join fetch a.b2");
hqlQuery.append(" inner join fetch a.c");
hqlQuery.append(" inner join fetch a.c.d");
hqlQuery.append(" where a.id = :id");
Query query = session.createQuery(hqlQuery.toString());
query.setLong("id", idList.get(0));
return (A) query.uniqueResult();V-B. Avantage▲
Comme vous vous en doutez si vous m'avez suivi jusqu'ici, cette solution est de loin la plus performante des trois. De plus, elle permet de contrôler au plus près le graphe des objets chargés.
V-C. Inconvénient▲
Si le chargement explicite apporte enfin des performances maîtrisables et acceptables, elle présente un prix à payer relativement important :
- le plus évident réside dans le nombre de méthodes à écrire. Alors qu'avec les deux premières méthodes, une seule méthode de chargement suffit, le chargement explicite se traduit généralement par des DAO conséquentes aux nombreuses méthodes ;
- l'écriture des méthodes de chargement devient plus technique qu'un simple load ou get Hibernate : la maîtrise d'Hibernate (différents types de jointures, HQL, criterias…) ;
- enfin, comme il n'est pas possible de débrayer le chargement à la demande natif d'Hibernate, tout accès à des propriétés non chargées se traduit soit par une requête en base de données, soit par une LazyInitialisationException si la session Hibernate a été fermée.
Règle n°2 : Ne mesurez jamais les performances en local
L'un des conforts de développement les plus trompeurs consiste à estimer les performances avec une base de données locale à l'application. Les temps de transfert réseau sont alors nuls, et les règles (notamment la première) et observations de cet article risquent fort de passer inaperçues… jusqu'au moment du déploiement !
Les mesures de performance doivent être effectuées de manière régulière avec un environnement de test réaliste (base de données sur un serveur distinct + jeu de données avec une volumétrie proche de celle estimée en déploiement).
VI. Chargement par interface▲
VI-A. Principe▲
Avec le chargement par interface, on sort ici des sentiers battus, puisque cette technique est le fruit de mon expérience. Elle permet de résoudre une bonne partie des inconvénients du chargement explicite, en gardant la maîtrise des associations chargées.
Le chargement par interface repose sur une interface de chargement, qui représente la vue de l'objet à charger.
Exemple : soit la classe du Domaine suivante :
public class Person
{
// Attributes
private Long id;
private String firstName;
private String lastName;
private Address address;
private Job job;
// Getters and setters
public Long getId() { return id; }
public void setId(Long id) { this.id = id; }
public String getFirstName() { return firstName; }
public void setFirstName(String firstName) { this.firstName = firstName; }
public String getLastName() { return lastName; }
public void setLastName(String lastName) { this.lastName = lastName;}
public Address getAddress() { return address; }
public void setAddress(Address address) { this.address = address; }
public Job getJob() { return job; }
public void setJob(Job job) { this.job = job; }
}On peut en extraire l'interface de chargement suivante :
public interface IWorker
{
public Long getId();
public void setId(Long id);
public String getFirstName();
public void setFirstName(String firstName);
public String getLastName();
public void setLastName(String lastName);
public Job getJob();
public void setJob(Job job);
}Il suffit alors de générer les requêtes de jointures par introspection afin de charger les associations contenues dans l'interface de chargement (méthode 'addFetchingStrategy') :
public Person loadById(Long id, Class businessInterface)
{
// Create query
//
StringBuilder hqlQuery = new StringBuilder();
hqlQuery.append("from Person ");
hqlQuery.append(addFetchingStategy(null, businessInterface));
hqlQuery.append(" where person.id = :id");
// Fill query
//
Query query = sessionFactory.getCurrentSession().
createQuery(hqlQuery.toString());
query.setLong("id", id);
// Execute query
//
return (Person) query.uniqueResult();
}
protected String addFetchingStategy(String association,
Class businessInterface)
{
StringBuider hqlQuery = new StringBuilder ();
// Association formatting
if (association == null)
{
association = "";
}
else
{
// Fetch on the association
hqlQuery.append(" left join fetch ");
hqlQuery.append(association);
association += ".";
}
// Get properties
Collection<PropertyDescriptor> descriptors =
BeanUtils.getPropertyDescriptors(businessInterface, null);
// Add fetching criterion
String fetchAssociation;
for (PropertyDescriptor descriptor : descriptors)
{
// Exclusion cases
Class type = descriptor.getPropertyType();
if ((type.isPrimitive() == true) ||
(type.getCanonicalName().startsWith("java") == true))
{
continue;
}
// Recursive fetching
fetchAssociation = association + descriptor.getName();
hqlQuery.append(addFetchingStategy(fetchAssociation, type));
}
return hqlQuery.toString();
}Note : ce bout de code s'appuie sur la classe BeanUtils de Spring pour récupérer les propriétés de l'interface de chargement. Il est bien entendu possible d'utiliser la librairie Apache commons-beans ou votre propre code à la place.
VI-B. Avantage▲
Cette méthode permet de résoudre les problèmes du chargement explicite :
- plus de lazy-loading ni de LazyInitialisationException : en manipulant l'interface de chargement, les classes n'accèdent qu'aux propriétés chargées et à elles seules. De plus, la vérification est effectuée à la compilation, et non à l'exécution ! ;
- l'objet sous-jacent reste une instance du Domaine, correctement initialisée et directement utilisable par Hibernate (à la différence d'un DTO _ cf. ci-dessous) ;
- le code ci-dessus étant dynamique, l'enrichissement d'une interface de chargement suffit à enrichir la requête en base de données. Ainsi, n'importe quel développeur, même peu au fait des mécanismes Hibernate, peut définir de nouvelles interfaces de chargement ;
- la couche DAO gagne en simplicité : une seule méthode, prenant en argument l'interface de chargement associée, suffit ! ;
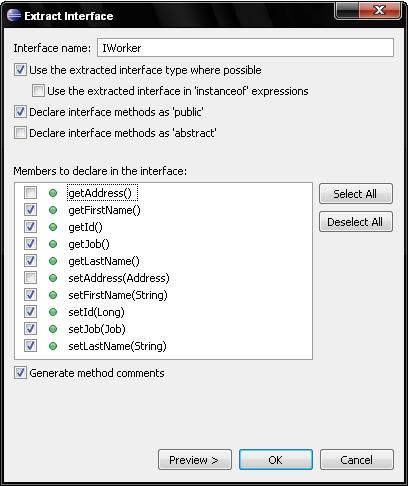
- Enfin, cerise sur le gâteau, grâce aux méthodes de refactoring Eclipse, un simple « Refactor -> Extract interface… » sur l'objet du Domaine permet de simplement définir l'interface de chargement en cochant le nom des propriétés associées :
VI-C. Inconvénient▲
Le principal inconvénient de cette technique est son… originalité. Elle n'est pas documentée ailleurs qu'ici, et le code n'est en rien officiel.
De plus, ce dernier n'est pas encore finalisé (il ne gère pas encore les dépendances circulaires ni les différents types de jointures), et j'hésite encore sur le packaging d'une telle solution (librairie Open-source ? contribution Hibernate ?).
Bref, le chargement par interface représente aujourd'hui plus une piste à explorer, notamment pour un nouveau développement, qu'une solution stable et éprouvée.
VII. Data Transfer Object▲
VII-A. Principe▲
L'usage des DTO est un héritage des architectures EJB2. Il consiste à toujours transformer les objets du Domaine en objets de transfert, qui ne contiennent que les données chargées.
On aura ainsi une classe du Domaine, et plusieurs DTO associées, celles-ci pouvant contenir des données issues de la jointure de plusieurs tables.
Il existe plusieurs solutions techniques pour utiliser des DTO. La plus simple est d'utiliser une librairie de conversion de beans Java, tels que Dozer ou BeanLib qui prennent en charge des telles problématiques.
De plus, Hibernate permet de définir simplement des objets créés à partir d'un ensemble de colonnes, issus d'une requête HQL :
Query query = _sessionFactory.getCurrentSession().createQuery
("select new com.package.UserDTO(user.firstName, address.cityfrom) from User user, Address address where …");VII-B. Avantage▲
L'usage de DTO apporte la même souplesse que les interfaces mentionnées ci-dessus : les données contenues dans l'objet manipulé sont chargées, et il n'y a pas de risque de LazyInitialisationException.
VII-C. Inconvénient▲
Le premier frein à cette technique est conceptuel : les couches supérieures à la DAO manipulent des objets qui n'ont plus de lien avec les entités du Domaine. C'est d'autant plus gênant que le principe même d'Hibernate (utilisation de simples POJO) a pour but de favoriser le Domain Driven Design.
De plus, si la génération des DTO à partir de classes du Domaine ne pose pas de problème particulier (on peut même les générer directement avec Hibernate, grâce au transformer AliasToBean), la répercussion des modifications d'une DTO vers une entité persistante peut poser divers problèmes non triviaux, concernant notamment la gestion de la concurrence, des proxys Hibernate, etc.
VII-D. Usage▲
Il est au moins un usage où les DTO sont particulièrement adaptés : le remplissage de liste de choix ou de grilles (en lecture seule) dans une IHM. En effet, les objets du domaine sont en général trop « gros », contiennent trop de données, ce qui peut pénaliser les performances de transfert et d'affichage.
Les DTO sont par contre des « poids plumes », qui ne contiennent que les données à afficher. Pratique et performant… tant qu'on ne cherche pas à les renvoyer en base ;-) !
VIII. Conclusion▲
Comme vous avez pu le constater à la lecture de cet exposé, il n'existe pas de solution miracle. De manière générale, votre choix devra se baser sur la taille du projet et la complexité de votre schéma de base de données :
- dans les cas les plus simples, l'utilisation du chargement à la demande, voire du chargement complet, peut être envisagée. Gardez cependant à l'esprit que si votre projet doit être amené à évoluer, un tel choix peut rapidement dégrader les performances de l'application ;
- généralement, je préconise le chargement explicite (ou sa dérivation en chargement par interface si le projet en est à son commencement). Cela nécessite un travail de développement et de formation des équipes plus conséquent, mais les performances sont toujours au rendez-vous ;
- enfin, l'approche DTO a tendance à péricliter, du fait de la complexification induite du modèle de données. Elle reste néanmoins utile pour le remplissage de liste de données simplifiées en lecture seule.
IX. Remerciements▲
Merci à RomainVALERI pour la relecture orthographique de cet article.